Intel presenta Latent Diffusion Model for 3D, su modelo de generación de imágenes 3D en 360º con IA
LDM3D permite a los usuarios generar tanto imágenes como mapas de profundidad a partir de un mensaje de texto
Intel Labs ha presentado una innovadora solución llamada Latent Diffusion Model for 3D (LDM3D), en colaboración con Blockade Labs. Este modelo de difusión utiliza inteligencia artificial generativa para crear contenido visual en 3D. Es el primer modelo en su sector capaz de generar un mapa de profundidad mediante el proceso de difusión para crear imágenes 3D con vistas de 360 grados que resultan vívidas e inmersivas. Esta tecnología tiene el potencial de revolucionar la creación de contenido, las aplicaciones metaversales y las experiencias digitales en una amplia gama de sectores, desde el entretenimiento y los videojuegos hasta la arquitectura y el diseño.
“La IA generativa tiene como objetivo mejorar la creatividad humana y ahorrar tiempo, pero la mayoría de los modelos actuales se limitan a generar imágenes en 2D, y muy pocos pueden generar imágenes en 3D a partir de mensajes de texto”, según destaca VasudevLal, responsable de inteligencia artificial y machine learning de Intel Labs,
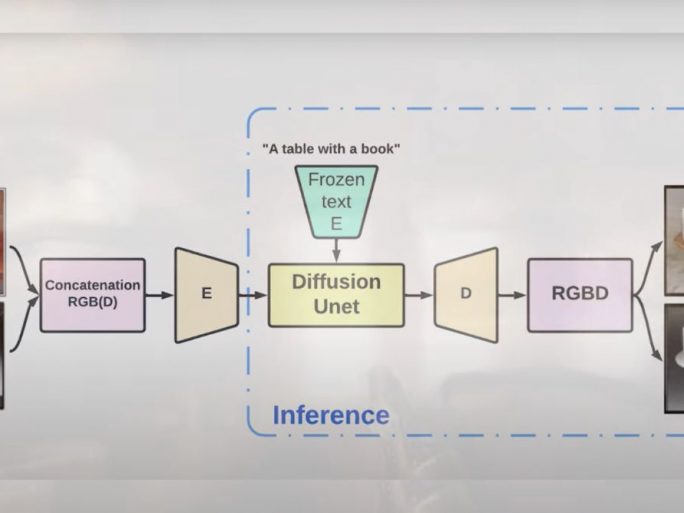
En este sentido, LDM3D destaca al permitir a los usuarios generar una imagen y un mapa de profundidad a partir de un texto determinado, utilizando casi el mismo número de parámetros que la difusión latente estable. Además proporciona una profundidad relativa más precisa para cada píxel de una imagen en comparación con los métodos estándar de posprocesamiento para la estimación de la profundidad, lo que ahorra a los desarrolladores un tiempo considerable en el desarrollo de escenas.
Mapas de profundidad desde un texto
La importancia de esta innovación radica en que los ecosistemas cerrados limitan la escala, y el compromiso de Intel con la verdadera democratización de la IA permite un acceso más amplio a los beneficios de esta a través de un ecosistema abierto. Hasta ahora muchos de los modelos avanzados de IA generativa se limitaban a generar únicamente imágenes en 2D. LDM3D rompe con esta limitación al permitir a los usuarios generar tanto imágenes como mapas de profundidad a partir de un mensaje de texto. Esto abre nuevas posibilidades en la interacción con contenidos digitales, ya que los usuarios pueden experimentar sus indicaciones de texto de formas antes inconcebibles.
El funcionamiento del modelo LDM3D se basa en el entrenamiento con un conjunto de datos construido a partir de una base de datos llamada LAION-400M, que contiene más de 400 millones de pares imagen-capítulo. Para anotar este corpus de entrenamiento, el equipo utilizó el modelo de estimación de gran profundidad Dense Prediction Transformer (DPT), que proporciona una profundidad relativa precisa para cada píxel de una imagen. El modelo LDM3D se entrena en un superordenador Intel AI equipado con procesadores Intel® Xeon® y aceleradores Intel® Habana Gaudi® AI, combinando la imagen RGB generada y el mapa de profundidad para generar vistas de 360 grados y experiencias inmersivas.
Para demostrar el potencial de LDM3D, los investigadores de Intel y Blockade desarrollaron una aplicación llamada DepthFusion. Esta aplicación utiliza fotos en 2D y mapas de profundidad para crear experiencias interactivas e inmersivas con vistas de 360 grados. DepthFusion utiliza TouchDesigner, un lenguaje de programación visual basado en nodos, para convertir indicaciones de texto en experiencias digitales interactivas.





